Azure Service Bus: concepts and strategies
Last few days I've been researching the concepts used by Azure Service Bus: a highly versatile and reliable messaging system that can be used to decouple your applications, and safely route / transfer your data to its destination. Below I listed some key concepts and strategies.
Queues
The sending application can enqueue messages on a queue. The queue will then store all messages until the receiving application processes the messages. Messages in queues are always ordered. When you implement a queue, it means you have a 1-to-1 connection. If you need to send the same message to 3 different microservices, you need 3 queues. In this model you place a lot of responsibility on the sending application, which has to send and distribute all 3 messages. Not ideal!

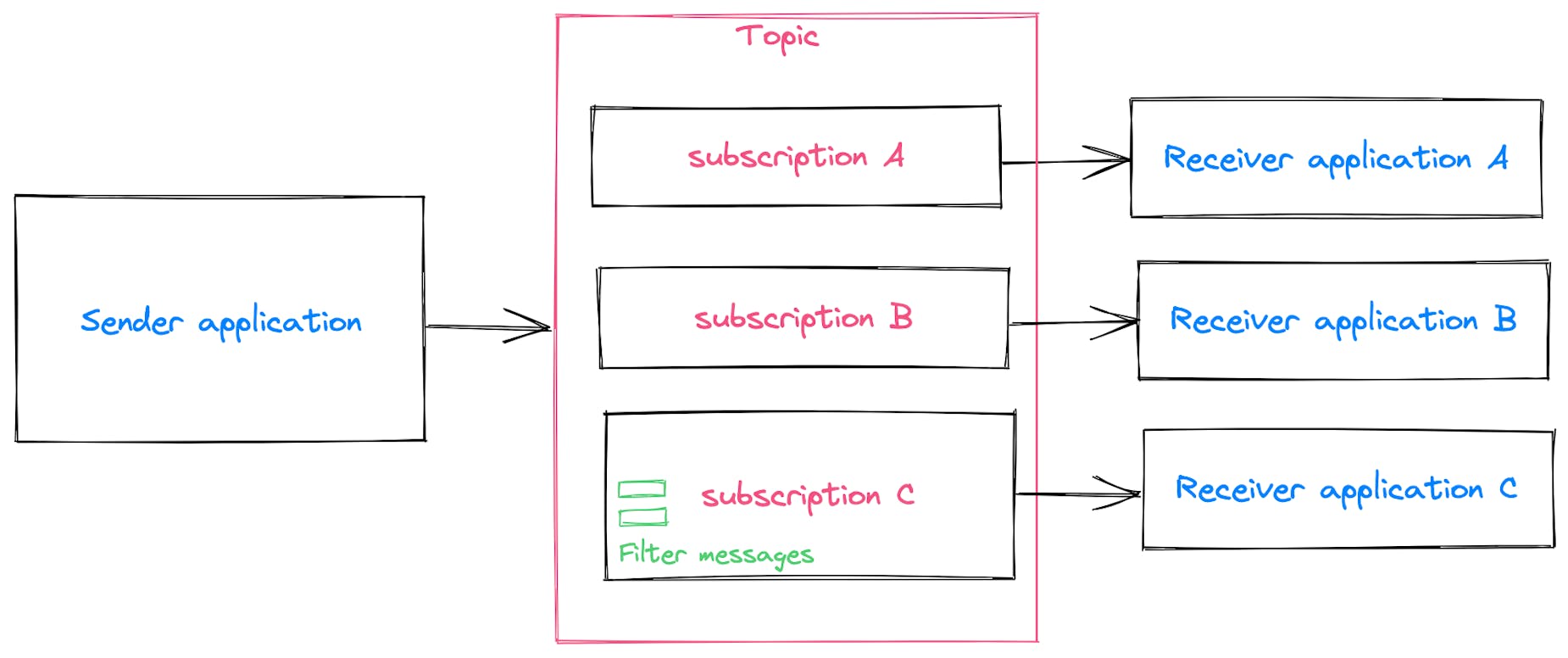
Topics and subscriptions
Besides a simple queue, you can use topics and subscriptions. This is also known as Publish-Subscribe messaging. The sending application pushes messages to a specific topic, and that message will be stored for each subscription separately. You can see it as a separate queue for each subscription. In my opinion this is perfect for working with microservices, as each microservice can have its own subscription (= queue!). Each subscription can have filters so they don't necessarily react to all messages in a topic.
A really cool concept we can apply here is installing a wiretap on a certain topic. This is basically the process of adding an extra subscription to a topic, and that subscription will be an application that will simply log the message properties. This way you can always see what is going on and is useful for debugging. You can even write code that will add this subscription on the fly, so you don't waste resources.
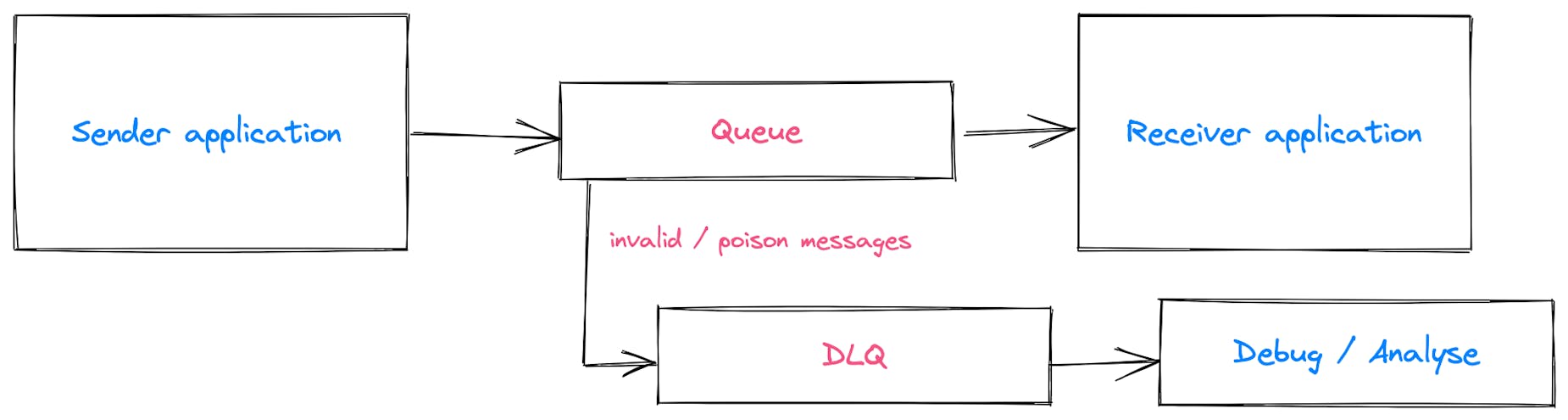
Dead-lettering
Service Bus supports a Dead-Letter Queue (DLQ), which basically means that invalid or poison messages can be moved to a separate queue. This is very useful as these messages can then be analysed, either manually or by a separate application.
Duplicate detection
Duplicate messages can be ignored when configured, which is very useful to ensure a message will only be processed once every X minutes. E.g. if you have a webhook that will enqueue messages. If the application doesn't return a response fast enough, the webhook might get called a second time, which will then send the message a second time to the queue. When this happens, the second message simply won't show up on the queue.

Message sessions
Related messages can be grouped together using a session id, and then processed together. You can think of the following use case: a receipt system. Each customer buys X amount of products in a store, the cashier will scan each product and this will get sent to a queue with a certain session id. Then the receiving application can use that id to group all messages and process it to generate a receipt for that specific customer.
Request-response correlation
Response messages can be correlated with the appropriate request messages to allow for two-way communication. This is great as we can now set up asynchronous two-way communication between applications.
Scheduled enqueue time
Messages can be sent to the queue with a specified enqueue time, which will then enqueue the item at a specific time.
Message deferral
Messages can be preserved on the queue and retrieved later for processing. E.g. when the receiving application can't process the message due to issues that aren't related to the message itself, we can then defer the message and process it at a later time. You can see it as setting aside a certain message.